


- メーカー
- エルザジャパン
- 型番
- NVIDIA H200 NVL 141GB
生成AIとHPCのためのGPU
NVIDIA H200 NVLは、市場を一変させるパフォーマンスとメモリ機能で生成AIとHPCワークロードを強化します。HBM3eを搭載した初のGPUであるH200の大容量かつ高速のメモリは、HPCワークロードのための科学コンピューティングを推進しながら、生成AIと大規模言語モデル(LLM)の高速化を促進します。

大容量で高速なメモリによる高いパフォーマンス
NVIDIA HopperアーキテクチャをベースとするNVIDIA H200は、毎秒4.8テラバイト (TB/s) で141ギガバイト(GB)のHBM3eメモリを提供する初のGPUです。これは、NVIDIA H100 Tensor コア GPUの約2倍の容量で、メモリ帯域幅は1.4倍です。H200の大容量かつ高速なメモリは、生成AIとLLMを加速し、エネルギー効率を向上させ、総所有コストを低減し、HPCワークロードのための科学コンピューティングを前進させます。
新たなレベルのパフォーマンスを体験
LLama2 70B 推論:1.9倍の高速化
GPT3-175B 推論:1.6倍の高速化
高性能コンピューティング:110倍の高速化
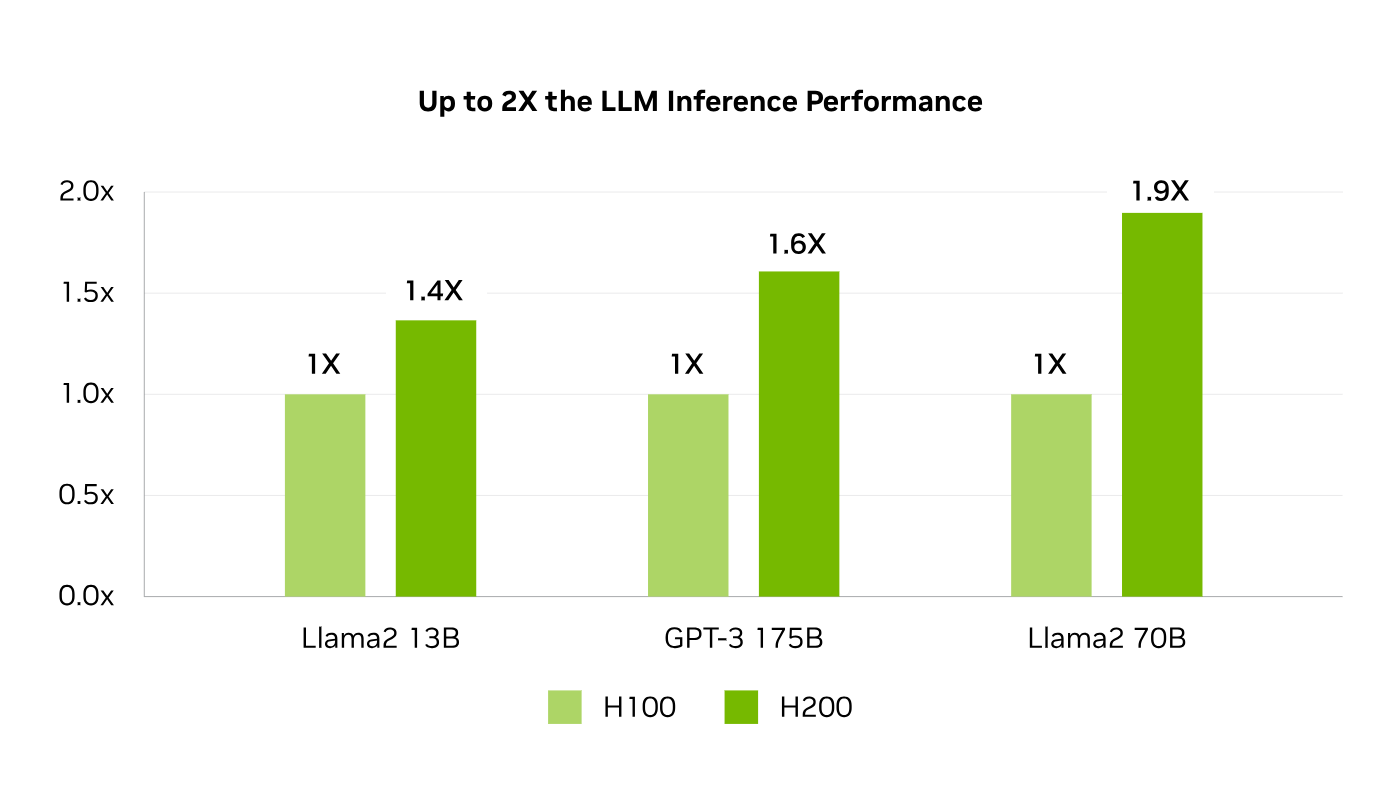
高性能なLLM推論でインサイトを引き出す
進化し続けるAIの世界では、企業はさまざまな推論のニーズに対応するためにLLMを利用しています。AI推論アクセラレータは、大規模なユーザーベース向けにデプロイする場合、最小のTCOで最高のスループットを実現する必要があります。
H200は、Llama2のようなLLMを扱う場合、H100 GPUと比較して推論速度を最大2倍向上します。
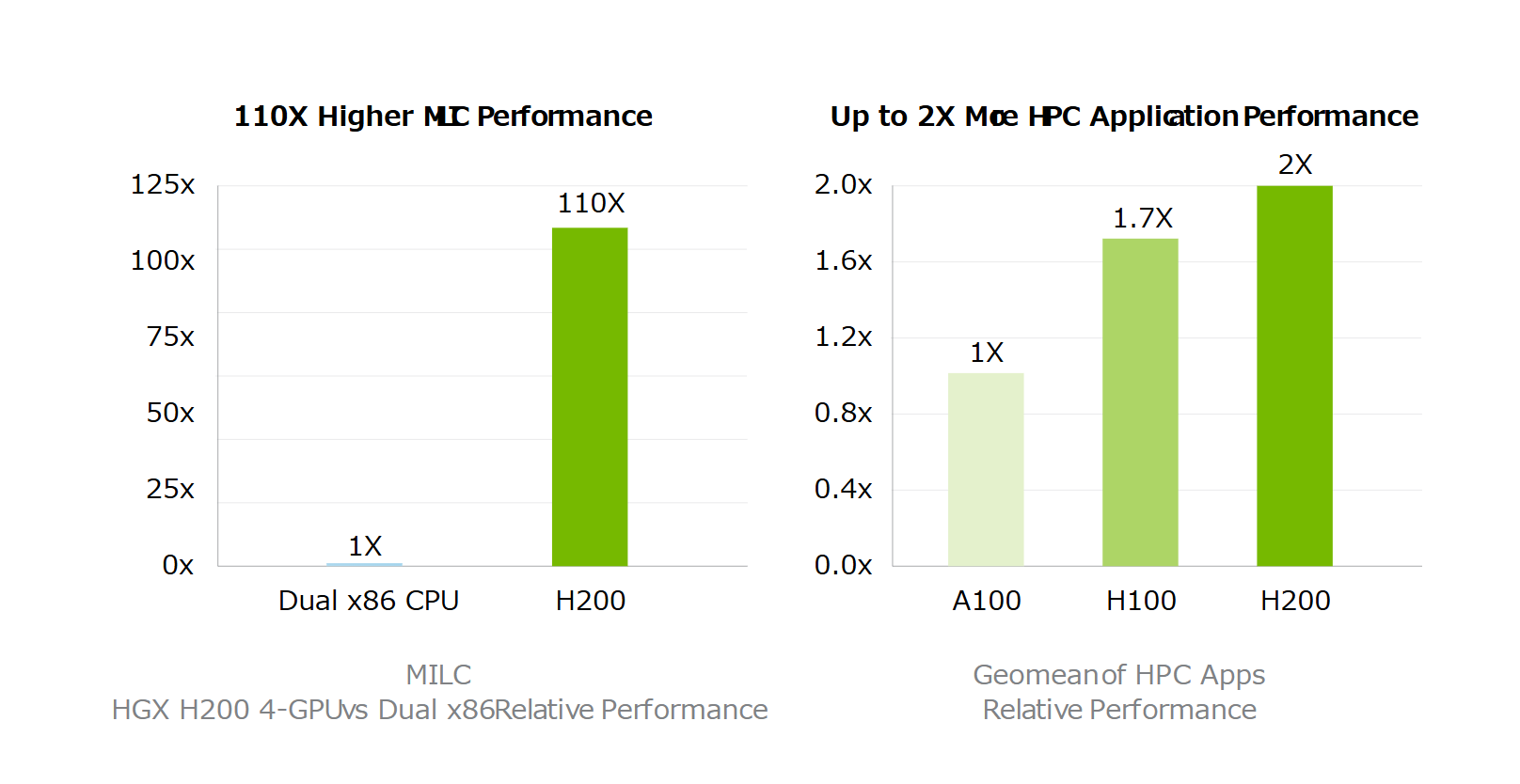
ハイパフォーマンスコンピューティングを
スーパーチャージ
メモリ帯域幅は、より高速なデータ転送を実現することで、ボトルネックとなる複雑な処理を削減するため、ハイパフォーマンスコンピューティングアプリケーションにとって極めて重要です。シミュレーション、科学研究、人工知能のようなメモリを大量に使用するHPCアプリケーションでは、 H200の高いメモリ帯域幅が、データへのアクセスと操作を効率化し、CPUと比較して110倍の早さで結果を得ることができます。
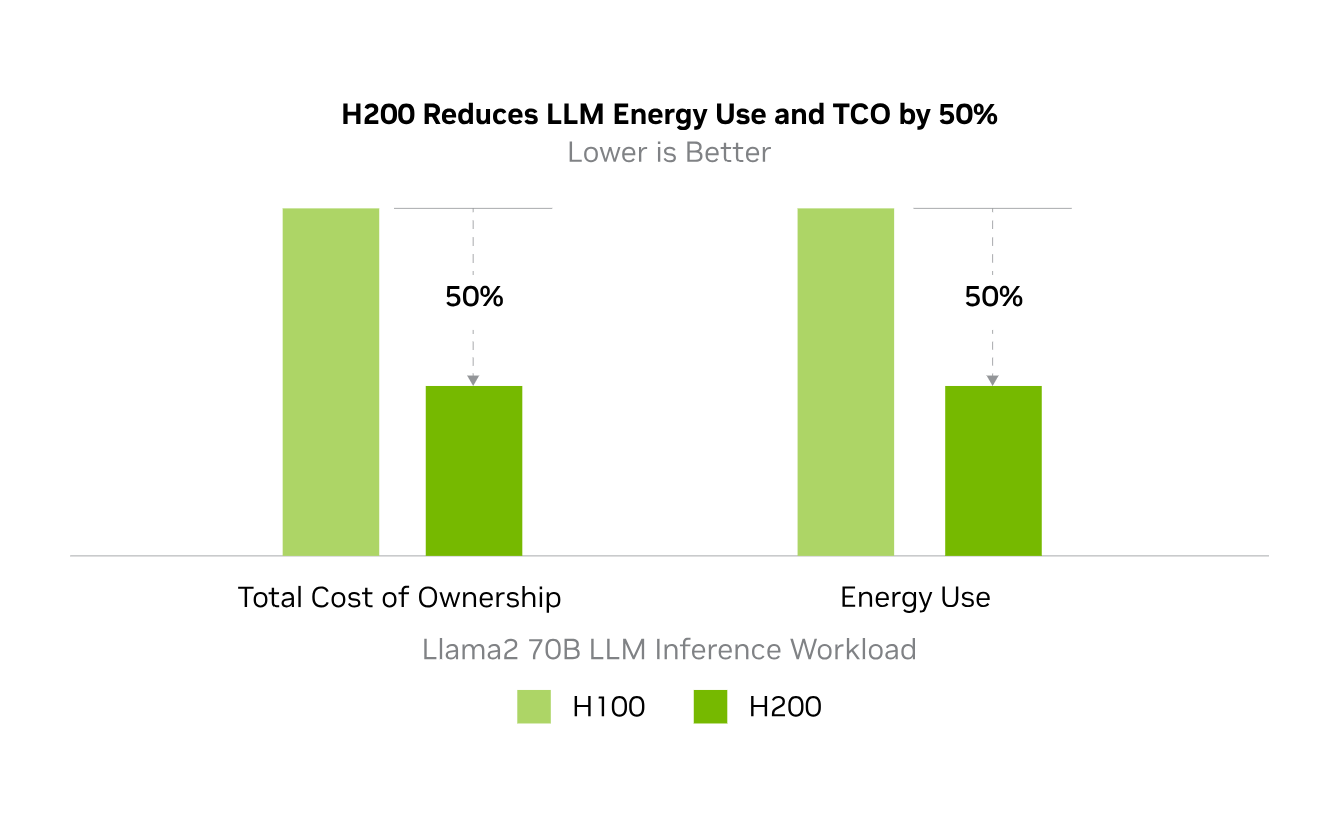
エネルギーとTCOの削減
H200の導入により、エネルギー効率とTCOが新たなレベルに到達します。この最先端のテクノロジは、すべてH100 Tensor コア GPUと同じ電力プロファイル内で、かつてないパフォーマンスを提供します。AIファクトリーとスーパーコンピューティングシステムは、高速なだけでなく、環境にも優しく、AIと科学のコミュニティを推進する経済的優位性を提供します。

エンタープライズ対応:
AIソフトウェアが開発と展開を合理化
NVIDIA H200 NVLは、5年間のNVIDIA AI Enterpriseサブスクリプションにバンドルされており、エンタープライズAI対応プラットフォームの構築方法を簡素化します。H200は、コンピュータービジョン、スピーチAI、検索拡張生成(RAG)など、本番環境対応の生成AIソリューションのAI開発と展開を加速します。NVIDIA AI Enterpriseには、エンタープライズ生成AIのデプロイを高速化するように設計された、使いやすいマイクロサービスのセットであるNVIDIA NIM™が含まれています。展開は、エンタープライズレベルのセキュリティ、管理性、安定性、サポートをもたらします。その結果、より迅速なビジネス価値と実用的な洞察を提供する、パフォーマンスに最適化されたAIソリューションが得られます。
お問い合わせ







